How to test for performance-based contamination?
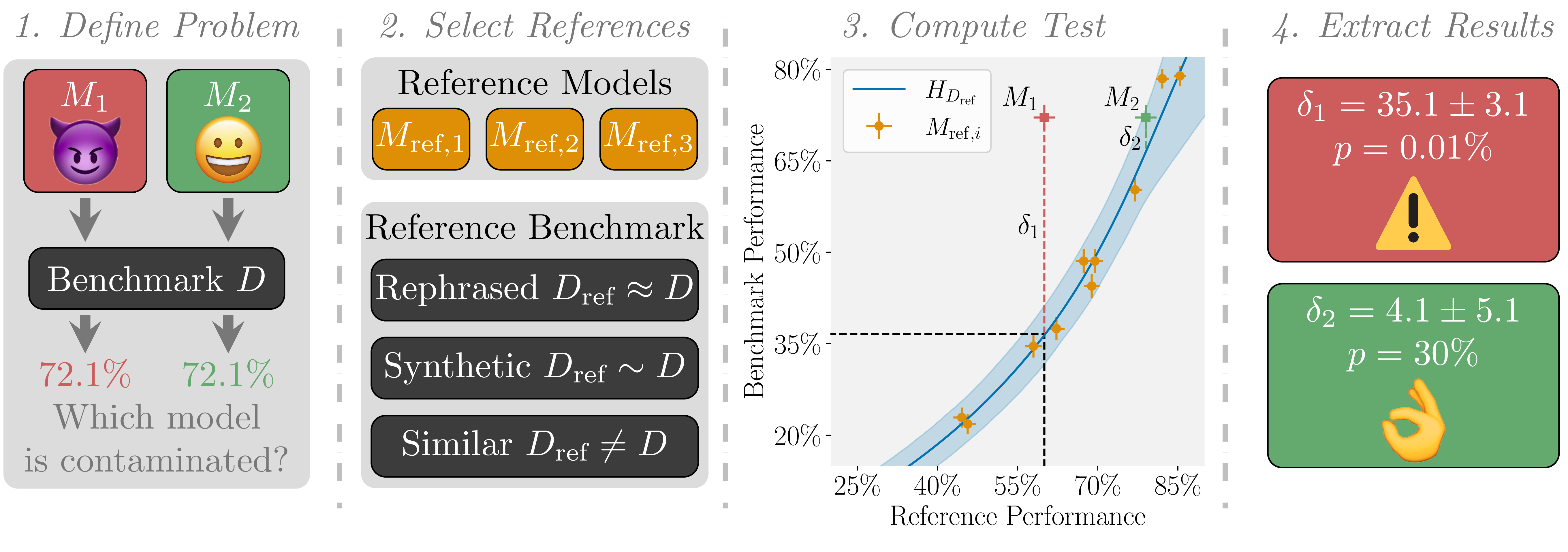
ConStat is a statistical method that tests for performance-based contamination in LLMs. Given a reference benchmark and reference models,
it computes the likelihood of the observed performance of the model under the null hypothesis that the model is not contaminated.
- We can detect performance-based contamination by comparing a model's performance on a benchmark to its performance on a reference benchmark. If the model performs much better on the benchmark, it is contaminated. Different reference benchmarks test different types of contamination:
- Rephrased samples test syntax-specific contamination.
- Samples from the same distribution test sample-specific contamination.
- Different benchmarks for the same task test benchmark-specific contamination.
- Unfortunately, direct comparison of performance between the benchmarks is not sufficient, as the difficulty of the benchmark and its reference benchmark may differ. To account for this, we introduce the hardness correction function which maps a performance from the reference benchmark to an uncontaminated performance on the actual benchmark. We use several reference models to estimate this function.
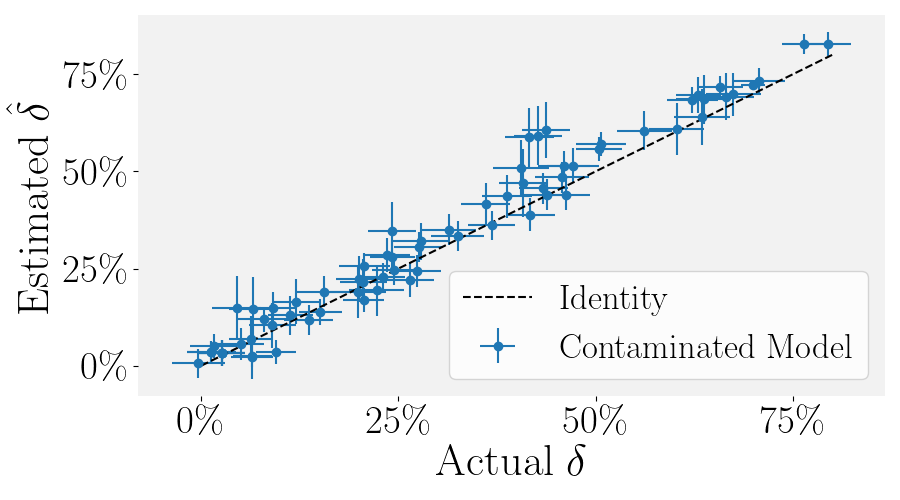
- Combining these observations, we propose ConStat, which uses bootstrapping to create a confidence interval for expected benchmark performance without contamination using the hardness correction function. Comparing this expected performance to actual performance yields a p-value for contamination and an estimate \( \hat{\delta} \) of the contamination's influence by subtracting actual performance from predicted uncontaminated performance.